Taxonomies vs Tagging: High Context, Low Context
We have to keep reminding ourselves, in taxonomy work, (a) how idiosyncratic and innovative human beings are in the way we structure our worlds; and (b) the difference between “high context” organisation systems (where you have to be educated into the original context/principle of ordering in order to be able to navigate it) and “low context” organisation systems (where it’s self-evident as soon as you get into it). I’ve taken this useful distinction from Edward T. Hall’s 1977 book Beyond Culture.
We have an experiment we do sometimes in taxonomy workshops. We ask participants to collect all the different ways they organise their music CDs. So far I think we’re up to 20 different ways, including one guy who organised his music in order of the girlfriend he was going out with at the time he bought it. That’s what I’d call a high context approach, obviously not self-evident to the general user (in fact, there’s probably a post-modernist Casanova movie idea in there somewhere). But there are other high context taxonomic systems that work quite well: engineering or scientific taxonomies, for example, where users can tolerate deep and specialised taxonomic hierarchies because they have been educated into them.
This issue of idiosyncratic or high context taxonomies isn’t new. David Weinberger recently blogged about Douglas Wilson’s 2001 book on the 18th century US president Thomas Jefferson’s bookish habits. (Thanks David, have just ordered from Amazon!) Apparently Jefferson compiled reading lists for law students, organised by the time of day that they should be read. David uses this example to push the “everything is miscellaneous” cause, and I’m not sure this is completely right… at least from the point of view of people who are trying to structure content for predictable access within organisations. Internet web content is a different story.
By chance I’m also reading Richard Wurman’s Information Anxiety 2 and here’s a phrase from Ramana Rao that struck me this morning as much more on the mark:
“Use the ‘grain of the wood’. Information has inherent structure, a grain. Trees, tables, time, documents, calendars, these are the spines that organise information. By designing tools based on such canonical information structures, they become potentially applicable in a wide range of situations.” (p.167)
Rao could be describing low context taxonomies when he refers to “canonical information structures” – take one look, and pretty much everyone will know how they work. Most of the corporate taxonomist’s work must be in discovering the shape of these canonical information structures within an enterprise, and shaping their taxonomies around them.
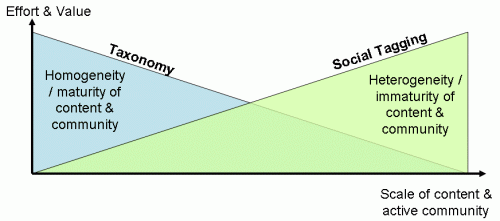
The exhilerating serendipity and scale of the web should not distract us from the virtues of (and need for) structuring and predictable patterns within a corporate environment. As Clay Shirky observed so accurately at the birth of the social tagging boom, the hierarchical taxonomy works fine on small content collections, but becomes increasingly unwieldy as the scale of content and community amplifies; social tagging on the other hand, amplifies ambiguity and confusion on small scales, but produces beneficial patterns at very large scales.
So maybe the enterprise taxonomist’s strategy needs to be like this: emphasising structure and relative control when collections and active communities are small, well defined, or relatively homogeneous; accommodating social tagging (used to be called “free” tagging in the good old days), and exploiting it more as content and active community grow?
9 Comments so far
- Patrick
Caught me there Louise

Actually that example is quoted from an essay by Borges “The Celestial Emporium of Benevolent Recognition” and I’m not sure it would fit my example here precisely, because it’s not just idiosynratic, but deliberately absurdist. But it’s a lovely example of “strange” taxonomies, you’re quite right.
Borges’ list is reproduced on wikipedia at http://en.wikipedia.org/wiki/Celestial_Emporium_of_Benevolent_Recognition
- Matt Moore
Love the diagram. Think i will steal it…
- Patrick
With due credit I hope
Glad you liked it!
- Emanuele
Great post Patrick and nice picture! If I’ve understood it right, (oversimplifying) you see a duality beetween taxonomies and emergent structures like folksonomies.
Here is my question: Are you complety sure that taxonomies and collaborative tagging cannot efficiently cohexist in medium-large systems aiming to an improved findability? Are you completely sure that what we already know about structured information cannot be used to improved the state of what we currently know as folksonomies?
I would really love your opinion on that!
Cheers,
Emanuele
- Patrick
Thanks Emanuele. Actually, I don’t see it as a duality, I believe both approaches can co-exist. They can also inform each other… for example, unstructured social tagging can be used to harvest alternate terms for a thesaurus linked to the structured taxonomy. There’s a nice discussion of this at http://taxocop.wikispaces.com/Social+tagging
Best
Patrick
- Emanuele
I’ve read already the discussion about Raytheon on the taxocop but what I’m talking about is not really the coexistence of taxonomies and folksonomies as two differents and complementaty tools. My idea is mixing these two approaches to produce a third way that lays somewhere in the middle.
I’ve talked about that also with David Weinberger and on my blog.
Cheers,
Emanuele
- Patrick Lambe
Hi Emanuele
I have done what I should have done the first time, and gone to your weblog to do some research. I find the work you are doing quite fascinating, and I love the way you are mixing up the different finding mechanisms into “findability cocktails”.
I’m still not sure this is a legitimate cohesive “third way” or simply using a combination of techniques appropriate to the environment, content and customers/consumers (I don’t like the term “users). If you take Amazon.com as an example, they have structured categories, tags, behavioural links (people who bought...also bought), reading lists, all of which provide a network of alternate, criss-crossing ways of arriving at related content. The key for me is that they are separate, but they are all accessible from the same place.
Tagging per se is, as you eloquently argue, still immature, I’d noted already the increasing tendency to create superordinate clusters, and I think there’s real value in the way you identify different ways of doing this. But I think these new ways that you describe will/should remain distinct from more structured approaches, and will deliver most value where you have large scale, fluid content, and large, hereogeneous communities accessing it. Thanks for sharing, going to put you on my blog roll, would like to keep track of what you are doing.
Best
Patrick
- Emanuele
Hi Patrick. Thank you again for your answer.
My comment wanted to be a little bit provoking. I read with interest your post and I really appreciated criticism or simply different views.
I’m sure that the evolution of tagging is still a fresh field and to further investigate the idea of ‘tagging ecologies’ I will present a research project to the Euro IA in Berlin this year named “FaceTag”.
Thanks for adding me to your blog roll and when you have 5 minutes to discuss a little..let me know
Cheers,
Emanuele
Page 1 of 1 pages
Comment Guidelines: Basic XHTML is allowed (<strong>, <em>, <a>) Line breaks and paragraphs are automatically generated. URLs are automatically converted into links.
I am surprised that you do not refer to Foucault’s Archaeology of Knowledge - I have always froun the example used in tyeh introduction of the way the Chinese emperor ordered his world most insightful - things that belonged to teh Emperor, things that are beautiful, things that from a long way off look like flies etc
Posted on June 23, 2006 at 07:54 AM | Comment permalink