Folksonomies and Rich Serendipity
In my post last week on “How to Killl a Knowledge Environment with a Taxonomy” I made fleeting reference to “rich serendipity” provided by folksonomies. I’d better explain what I meant by that.
What makes folksonomic tagging activity different from “free text” keywords entered into optional metadata fields by publishers of content into content management systems? Why does the serendipity afforded by such (user contributed) keywords seem less powerful than folksonomic tagging? The answer lies in people as knowledge aggregators.
The real difference between uncontrolled keywords and folksonomic tagging is that in closed content management systems, the “free text” keywords usually sit unobserved behind the scenes, waiting for a search engine to match them to a search term. In the classic folksonomic sites, the tags are exposed to everybody and they become social property. I can do a random search on Delicious or Flickr and find a piece of content I like. I can see the tags, and chase those, to find other items tagged by the same person with that tag, or items tagged by other people using the same tag. If I have permission, I can tag their content with my own tags. If I want my items to come up in the same searches as other peoples’ items that I like, I’ll adopt and use their tags.
Socially exposing the tags has some interesting effects, and this is where Thomas Vander Wal’s definition of a “folksonomy” comes into play:
“There [is] tremendous value that can be derived from this personal tagging when viewing it as a collective when you have the three needed data points in a folksonomy tool: 1) the person tagging; 2) the object being tagged as its own entity; and 3) the tag being used on that object… keeping the three data elements you can use two of the elements to find a third element, which has value. If you know the object (in del.icio.us it is the web page being tagged) and the tag you can find other individuals who use the same tag on that object, which may lead (if a little more investigation) to somebody who has the same interest and vocabulary as you do. That person can become a filter for items on which they use that tag.”
If we look at the trail I described from a random keyword search to an object I liked, to the tags used on that object, to other objects using the same tag, the trail looks like random serendipity. But web searches and hyperlink trails also follow random serendipity, so it’s hard to explain the explosion of enthusiasm around social tagging – not an explosion of theoretical interest, but of actual use, implying usefulness. This type of serendipity seems different, more valuable.
The triad of elements that Vander Wal describes in folksonomies (socially exposed personal tagging) seems to hold the key, and the real key is the element in the triad that most observers (especially taxonomists) miss. The really interesting part of a folksonomy is not the content item being described, and not the tags that describe the item, but the person doing the tagging.
Person-mediated Serendipity Trails in Folksonomies
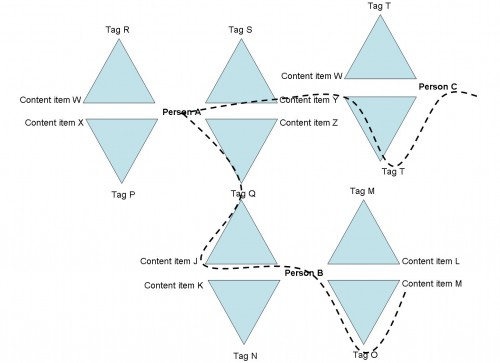
Most taxonomists assume (not incorrectly) that the useful categorization of content requires the intellectual analysis of that content’s subject matter, according to the predefined structure of the taxonomy. So the taxonomy itself is an over-arching organizing framework. But this involves a fairly high cognitive cost in formal categorization, not to mention possible anxiety over accuracy and precision in using somebody else’s categorization structures and systems (Sinha 2005; McMullin 2004).
What Vander Wal realized is that socially exposed tagging for personal use introduces another organizing agent that compensates for the ambiguity of its vocabulary with high-value serendipity: people. We are much better at picking up information and knowledge cues based on perceived similarities and differences compared to other people, than we are at picking up clues from a people-free environment. If people-free environments gives us weak serendipity, person-mediated serendipity is much richer.
People are a useful organizing agent because they are natural knowledge attractors and aggregators of meaning. People habitually collect and arrange for themselves what Vander Wal calls “personal infoclouds” and these arrangements reflect a meaningful perspective on knowledge (Vander Wal 2006).
Like the seventeenth century scientists with their cabinets of curiosities, we all collect – and arrange around us – things that we find interesting and useful. And when we tag them publicly and make the tagged content accessible publicly, we are revealing aspects of our sensemaking activity and our information and knowledge landscapes.
Now some of that landscape is shaped, contoured and described in highly individualistic, private, inaccessible ways (the Babel Instinct at work). But other parts are more publicly accessible, and will resonate with the interests, common activities and needs of other people. We can learn from other people’s structured or semi-structured infoclouds, and as the diagram above shows, we don’t need to invest the high cognitive cost of analysis and matching to a predefined structure to do so. I tag for myself, you learn.
I can click on a tag that both you and I used, and it will show me content that has been attached to that tag by anyone, including you and I. If I notice that several content items of interest come from the same few people, I can go look for their personal info-clouds. I can learn their vocabularies and adopt or adapt them if I find them useful. In so doing, I am also exposing my content to them. What we have, effectively, is emergent and naturalistic common ground and boundary spanning work going on at the micro, personal level.
Despite the early enthusiasm for folksonomies, there are some heavy costs and constraints built in, however. Rich serendipity requires very large volumes of content and a large, diverse contributing population. With smaller and less diverse volumes of content, and smaller contributing populations, the serendipity payoff weakens, because fewer concentrations of like-interests are possible. Think of the difference between a village and a city in terms of giving access to deep, similar, highly personalized interests.
The cognitive ease of using our own personal categorization vocabularies (and those that we decide to adopt or adapt from the resonant personal infoclouds of others) and the lack of vocabulary control is a benefit. But this is matched by very high ambiguity in the collective vocabulary of the shared resource, and very low precision amounting to meaninglessness in many cases. In October 2006 for example, there were 770,000 photographs hosted on Flickr tagged with the word “me”. This, along with other self-referential tags are only useful within the personal collections of members and not in the common language space.
So if you’re interested in folksonomies and social tagging, think about why. If you’re just locked onto getting cheap metadata, you might forget to provide for the social navigation of vocabularies, and miss what folksonimies are really good at – rich serendipity.
This is another extract from my forthcoming book Posted by Patrick Lambe on 20/10/06 at 07: 27 PM | Categories: Taxonomy | Permalink
2 Comments so far
I read with this post with great interest.
Just the other day I observed a lesson where a teacher was working with a student one-on-one in a reading lesson. The student was an early reader struggling with the reading process. She was learning the difference between short “e” and long “e”. The teacher gave her several word cards and asked her to organize them into groups. The activity took much longer than the teacher had planned, however it was fascinating to watch the student organize the words and then re-organize them for meaning. It is a lot like tagging and folksonomies – organizing information and knowledge.
Page 1 of 1 pages
Comment Guidelines: Basic XHTML is allowed (<strong>, <em>, <a>) Line breaks and paragraphs are automatically generated. URLs are automatically converted into links.
Another excellent article. Very topical for me at present because I’m trying to convince a client to use a tagging/folksonomy approach in preference to a file plan and taxonomy for organising content on their recently launched community web site, for which I’m spec’ing the next phase development (see http://www.communities.idea.gov.uk)
Posted on October 22, 2006 at 05:25 PM | Comment permalink